Project 3: Essay Grader
Overview
- We will implement a simple bag of words model as our baseline and improve upon that.
- We will train different machine learning algorithms using the features extracted from the training essay.
- A neural approach to essay grader. (Using the word embedding to train a recurrent layer composed of Long Short Term Memory.)
Table of Content
- Introduction
- Data Set
- Our Approach
- Evaluation Metric
- Baseline Model
- Feature Extraction
- Learning Algorithm
- Introduction to neural approach
- Word2Vec
- Feed Forward Neural Network
- Recurrent Neural Network
- Training
- Result and Discussion
- Conclusion
1. Introduction
Essay scoring is the task of assigning a number to an essay by a professional teacher or grader. While automated essay scoring (AES) is a computer program that assigns a score to an essay without the intervention of humans. AES is an application of Natural Language Processing (NLP) and Machine Learning (ML). In 1966, Ellis Batten Page came up with an idea of an AES system called Project Essay Grader (PEG). Every year hundreds of thousand essays are scored by teachers. Scoring essays in huge quantities takes a lot of valuable time and is also costly. Manual scoring of essays is also a very tiring job for teachers. With the help of the AES system, the teacher can focus on teaching rather than scoring the essay. The number of students going abroad from Nepal for higher study is increasing significantly over the past few years and the number doesn’t seem to stop. The students have to pass the English proficiency test like IELTS and TOEFL where they have to write an essay in writing test. To ace, the writing test they have to practice a lot, scoring those essays takes a huge amount of time. An AES system can be very useful in such a scenario, providing instant results to students. The goal of this project is to provide an AES system that can yield fast, effective and affordable solutions on essay scoring tasks.
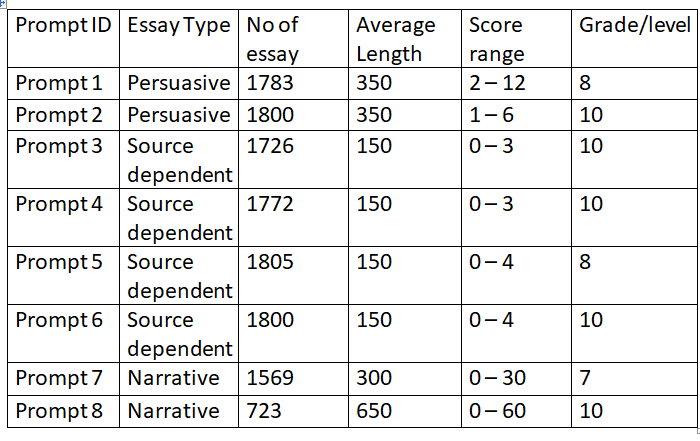
2. DataSet
The data for this project is obtained from a past Kaggle competition. The dataset consists of approximately 13000 essays across 8 prompts. Following is the list of 8 prompts.
- Prompt 1: Write a letter to your local newspaper in which you state your opinion on the effects computers have on people.
- Write a persuasive essay to the newspaper in which you state your opinion on the effects computers have on people.
- Prompt 3: Write a response by reading “Rough Road Ahead” by Joe Kurmaskle that explains, how the features of the setting affect the cyclist.
- Prompt 4: Read the Winter Hibiscus by MintonyHO and explain why the author concludes the story with the last paragraph.
- Prompt 5: Read the “Narciso Rodriguez” by Narciso Rodriguez and describe the mood created by the author.
- Prompt 6: Read “The morning Mast” by Marcia Amidon lusted and describe the obstacles the builder of the Empire State Building faced in attempting to allow dirigibles to dock there.
- Prompt 7: Write a story about a time when you were patient.
- Prompt 8: Tell a true story in which laugher was one element or part.
The dataset includes an essay of three types:
- Persuasive essay: In a persuasive essay, the writer has to convince the reader to accept a particular point of view or take a specific action.
- Source dependent essay: In a source dependent essay, the writer has to write a response to the given text.
- Narrative essay: Narrative essays are like telling a story.
The table below shows the description of the dataset.
3. Our Approach
We can follow two approaches to solve this problem. Firstly we can train and test on a single prompt which allows us to exploit the specific knowledge of a single prompt to more accurately increase the score to test essays. Another approach is to train on all the training essays and test them on test essays of different prompts which allows to train for a larger set and leverages the knowledge of the whole training set. This approach is similar to transfer learning. This problem can be viewed as a regression task where the goal is to predict a single number or as a classification task where the goal is to assign a class to an essay. We will approach this task as classification which will be necessary for evaluating our model with the evaluation metric Quadratic Weighted Kappa (QWK). We will implement a simple bag of words model as our baseline and improve upon that. Then we will train different machine learning algorithms using features extracted from training essay and bag of words features. Following that, we will also use a neural approach to solve this task where we get the word embedding to train different variants of neural networks (feed-forward network, recurrent network).
4. Evaluation Metric
The most widely used evaluation metric for the AES system is Quadratic Weighted Kappa (QWK) which measures the agreement between two raters. The range varies from 0 to 1 where 0 is a random agreement between raters and 1 is a complete agreement between raters. In the event, if the agreement between the raters is less than by chance then this metric may go below 0. In our case, the quadratic weighted kappa is calculated between model score and human score on each set of essays. Other used metrics are mean absolute error(mae), mean squared error(mse), Pearson’s correlation coefficient, and spearman’s correlation coefficient, etc.
5. Baseline Model
In this section, each essay is converted into a bag of words which then will be used in a simple logistic regression algorithm for the prediction of the score. To convert essays into a bag of words, we have to do some preprocessing on the essay. First of all, we will remove punctuation, full stop, question mark, exclamatory sign, and numbers. After that, we will remove the stopwords from English and some other anonymization words like PERSON, ORGANIZATION, EMAILS, etc which are used to protect the personal information of the writer. We are using all the essays from different prompts which have different score ranges. So we have to normalize the score in the range of [0,1]. Since we approached this task as classification we rescale the score in the range [0,10] and round off to the nearest integer. Now, we will use the CountVectorizer method from the sklearn library to get a bag of words and use a logistic regression algorithm. The test set hasn’t been released so we have to split training data into train-test (90%-10%) set. The QWK score of our baseline model is 0.69.
6. Feature Extraction
Feature extraction is a general term for constructing new features from original features where the original features get too large or can’t be directly used. When we construct new features then the extracted features should describe the original data. Features extraction is the most important part of any machine learning task. Previously developed AES systems have heavily utilized hand-engineered features for this task. While recently developed neural networks omitted the need for feature engineering. We have extracted features like word count, sentence count, unique word count, various parts of speech such as noun, adjective, adverb, verb, etc. We have also extracted spelling error counts, grammar error count, and punctuation counts. We used python libraries like nltk, spacy, and spell checker for feature extraction.
7. Learning Algorithm
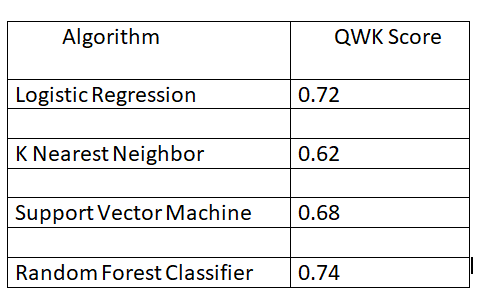
We will use both the extracted features and bag of words features to train different machine learning algorithms. The algorithms used are:
- Logistic Regression
- K Nearest Neighbors
- Support Vector Machine
- Random Forest Classifier
-
Logistic Regression:
Logistic regression is one of the classical classification methods. It is the most commonly used algorithm for solving a classification problem. Logistic regression can be used for binary classification i.e. when the target variable has two classes and multinomial classification i.e. when the target variable has more than two classes. Logistic regression is named for the function used logistic function. The logistic function is also called the sigmoid function. The logistic function gives an “S” shape curve that can take any real value and map it into a value between 0 and 1. If the output of the function is greater than 0.5, we classify the output as 1 and if the output is less than 0.5, we classify the output as 0. Below is the figure of the sigmoid function.
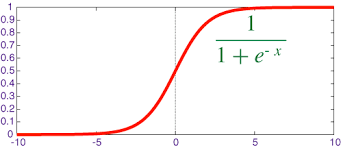
Image Source: From Wikipedia
-
K Nearest Neighbors:
KNN is a non-parametric classification method. It is used for classification and regression problems. It is one of the simplest algorithms. The key idea of the KNN algorithm is nearby point belongs to the same class. KNN algorithm makes no assumptions about the data. It computes the distance between the testing points to every training example. Then select the k closest instances and their labels. It output the class which is most frequent in labels. The training time of the KNN algorithm is zero while the testing time can become very large with a large number of data points in the dataset. This algorithm can be computationally expensive because we need to store all training examples and compute the distance to all training examples for a single prediction. Below is the figure of how the KNN algorithm works.
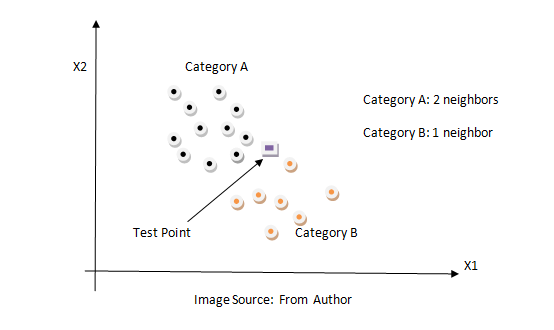
-
Support Vector Machine:
Support Vector Machine is a supervised learning model that analyzes data for classification and regression analysis. It constructs a hyperplane in high dimension space which can be used for classification or regression. It finds a hyperplane that has the largest distance to the nearest training data points. The closest points are called support vectors and hence algorithm is termed a Support Vector Machine. The distance from the nearest training point to the hyperplane is called margin. It tries to maximize the margin. So SVM is also called a max-margin classifier. Max margin can reduce the effect of mislabelled data than min margin and it generalizes better in the future for unseen data. SVM is effective in high dimensional space because data are likely to be linearly separable in high dimensions than in low dimensions. Below is the figure SVM algorithm.

-
Random Forest Classifier:
Random Forest is an ensemble learning method for classification and regression problems. A random forest fits several decision trees on various sub-sample of the dataset and outputs the class that is the mode of the classes for classification problem and mean/average of the individual tree for a regression problem. A decision tree is a very powerful and intuitive model. The idea of the decision tree is to divide the space into different regions and fit a very simple model to each region. The model can be linear or constant. To divide into different spaces we use a simple if-else rule that provides branching. We need to select the best attribute/features to generate the branching. To select the attribute at the root we can use some criterion like information gain, gini index, etc. In the case of information gain, we find the gain of all attributes and attribute with the highest gain is placed at the root, and a branch with entropy greater than 0 needs further splitting. In this way, we can create a decision tree. Decision trees suffer from overfitting but random forest controls the problem of overfitting. In a random forest, features and datapoint are randomly chosen so that the tree is independent of each other as a result it reduces the high variance problem of the decision tree. Below is the figure of the decision tree.
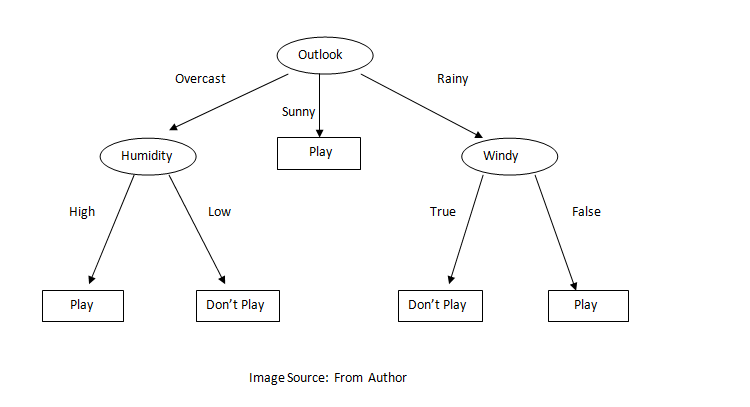
Below is the result of the different machine learning algorithms.
8. A neural approach
In this section, we will describe a new solution to solve the AES problem. The previous method that we have used is inspired by the hand-engineered features which are carefully extracted from the essay. Most of the time it requires domain knowledge to extract important features which can be very difficult and time-consuming. The process of handcrafted features can be eliminated by a new deep learning algorithm. The major difference between deep learning and the traditional method is that deep learning automatically learns features from the data instead of hand-crafted features. The features extracted from such algorithm are fed into different neural network architecture such as feed-forward neural network, recurrent neural network, etc, and the desired output is obtained (in our case we want the score of the essay). For the AES task, we will use the word2vec algorithm to extract features (word embedding) from essays.
9. Word2Vec
Word2Vec was developed by Thomas Mikolov in 2013. The main goal of the Word2Vec paper was to introduce a technique that can be used for learning high-quality word vectors from huge datasets. Word2Vec is a way to represent words in some vector space such that similar words are close to each other and dissimilar words are far apart. There are two models for Word2Vec:
- Continuous Bag of Words
- Skip Gram
- Continuous Bag of Words: The CBOW predicts the current word based on the context. The architecture of the CBOW model consists of the input layer, projection layer, and output layer where the input is the history and future words and output is the current(middle) word.
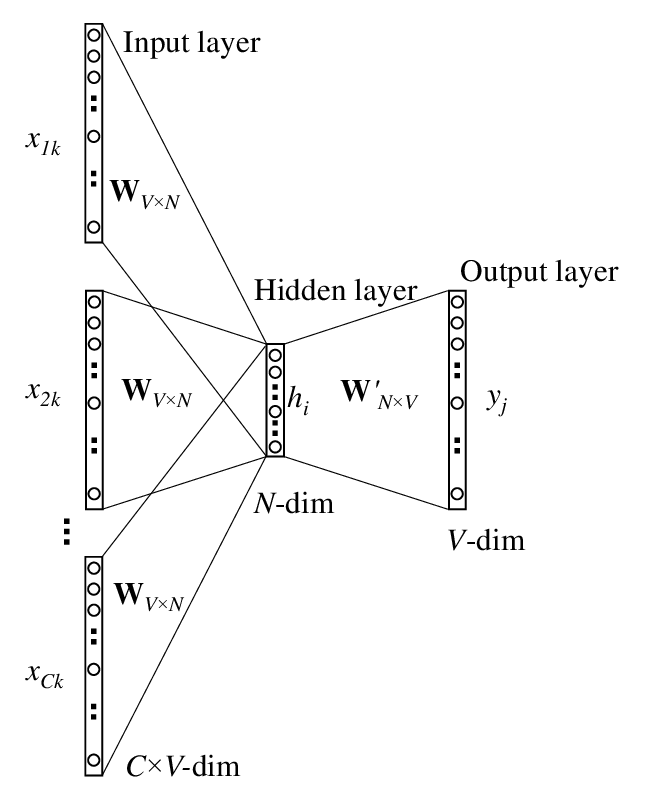
Architecture of CBOW Model
Image Source: https://www.researchgate.net/figure/The-skip-gram-model_fig3_268226652
- Skip Gram: The skip-gram architecture is similar to CBOW, but instead of predicting the current word, it tries to predict the surrounding words given the current word. It uses the current word as an input to predict words within a certain range before and after the current word. We will train a simple neural network with a single hidden layer to predict the surrounding words and use the weights of the hidden layer as word embedding/vector.
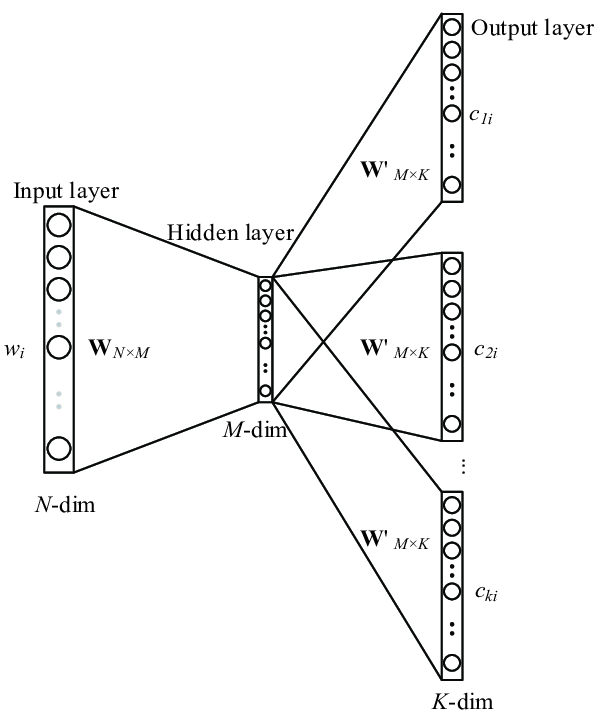
Architecture of Skip Gram Model
Image Source: https://www.researchgate.net/figure/The-skip-gram-model_fig3_268226652
10. Feed Forward Neural Network
Feedforward neural network is the simple form of neural network. A simple feed-forward neural network is illustrated in the below figure.
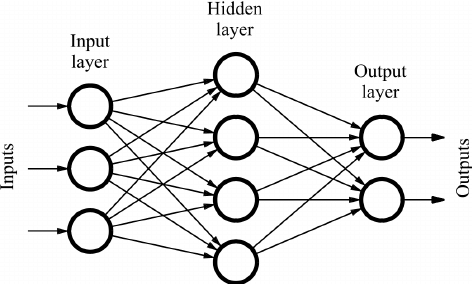
Architecture of FeedForward Network
Image Source: https://www.researchgate.net/figure/Sample-of-a-feed-forward-neural-network_fig1_234055177
Each of the circles in the figure represents a single neuron. A neuron is a computational unit that takes n input and produces a single output. The parameter (weights) used in computing output makes the difference in a neuron. The most popular choice for the neuron is the ‘sigmoid’ unit. Each neuron can have incoming and outgoing arrows. We can stack the different n numbers of the neuron to make a layer. Every neuron can be connected to every neuron in the next layer making it a fully connected layer. At the output, there can be a single neuron or multiple neurons according to the task either regression or classification.
11. Recurrent Neural Network
Recurrent Neural Network (RNN) is a class of artificial neural networks. Compared to feed-forward network and convolution neural network, RNN don’t work on fixed grid i.e. the input and output doesn’t have to be fixed-sized vector. RNN also captures the long-term dependency among the data which makes RNN more powerful and capable of learning more complex patterns from data. RNN is widely used in language modeling because it can capture the sequential information present in the input data i.e. dependency between the word in the text while making a prediction.
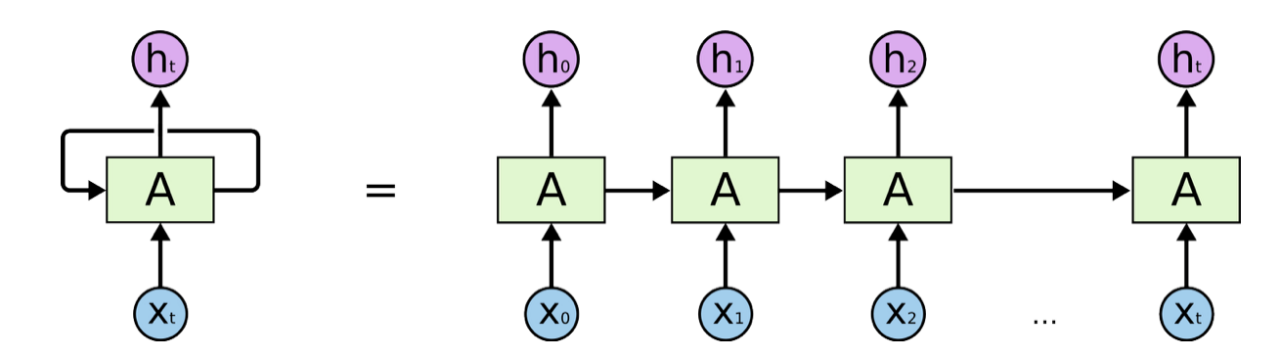
Architecture of RNN
Image Source: https://www.knime.com/blog/text-generation-with-lstm
The above figure introduces the RNN architecture where a rectangular box is a hidden layer at a time step t. Each such layer holds several neurons each of which performs a linear matrix operation on its inputs followed by a nonlinear operation. At each time step, the output of the previous step along with the next vector is input to the hidden layer to produce a prediction yˆt and output features ht.
ht = σ(W(hh)ht−1 + W(hx)x[t])
yˆt = softmax(W(S)ht)
The problem arises in RNN during its training. Since we are multiplying the same matrix each time during forwarding propagation, we also multiply the same matrix at each time step during backpropagation. If the value of the matrix is less than 1, then the gradient vanishes so it can’t learn long-term dependency or if the value of the matrix is greater than 1, then the gradient explodes.
The exploding gradient problem can be solved by using weight clipping i.e to clip gradients to a small number whenever they explode. To deal with vanishing gradients, other types of RNN models are more suitable such as Long Short Term Memory (LSTM). LSTM is good at learning long-term dependency as it uses different gates like input, forget and output gate. All three gates control the flow of information during the processing of the input sequence. The hidden state of LSTM is broken into two parts i.e cell state and hidden state. Cell state will store all the information also called memory internal. Forget gate is responsible for deciding what information should be removed from the cell state. Input gate is responsible for dealing with what information should be stored in a cell state. Output gate is responsible for deciding what information should be taken from the cell to give as an output. Following is the figure and equation of LSTM:
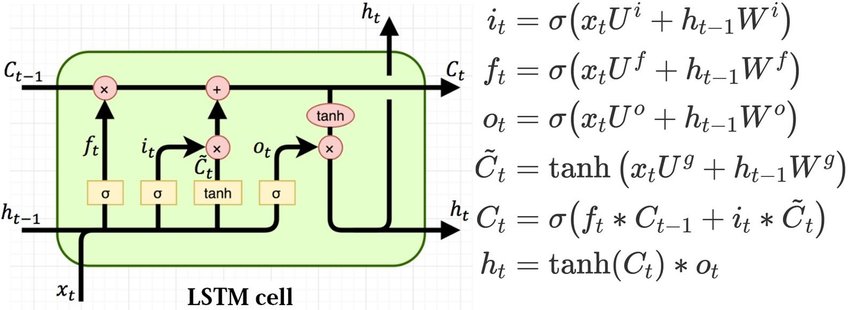
Image Source: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
12. Training
For training a neural network, we combine both the hand-engineered features and word embedding. We normalize the score in range [0,1] and train the model using adam optimizer to minimize the mean squared error. To calculate the QWK score we multiply by 10 and round off to the nearest integer. This process achieves a higher QWK score rather than training using a classification approach with neural networks. But this process doesn’t have significant improvement with the machine learning model. We also use dropout to avoid overfitting. Since we don’t have testing data, the cross-validation approach is used to train and test the model. As we have an essay from different sets, stratification (it preserve the percentage of sample from each set) is also implemented in the cross-validation method.
13. Result and Discussion
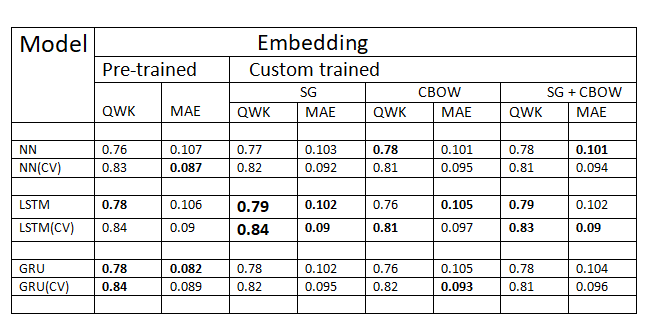
The results of various networks are shown in the above figure. The LSTM model outperforms the baseline model by 10% on quadratic weighted kappa. According to the above results, all the models were able to learn the task properly. The LSTM slightly outperforms other models. The word embedding of skip-gram performs better than other variants. Additionally, we perform cross-validation and the results were greatly improved. With cross-validation, the results were increased by 5%.
14. Conclusion
In this project, we proposed an approach based on a recurrent neural network to solve the task of automated essay scoring. We investigated both hand-engineered and neural network methods for feature extraction. We also explored the combination of hand-engineered and automatically learned features. The combined method outperforms the baseline model by 11%. Finally, the goal of this project to create a web application that can grade the essay written by students which can help to improve their writing skills was achieved.
15. Links
The whole code can be found Here
The original dataset can be found Here